The Language of Life (Part 6): Closing the Loop—From In Silico Design to In Vitro Data
By Ryan Wentzel
3 Min. Read#Drug Discovery & Biology#active-learning#lab-automation#self-driving-lab#ML-ops
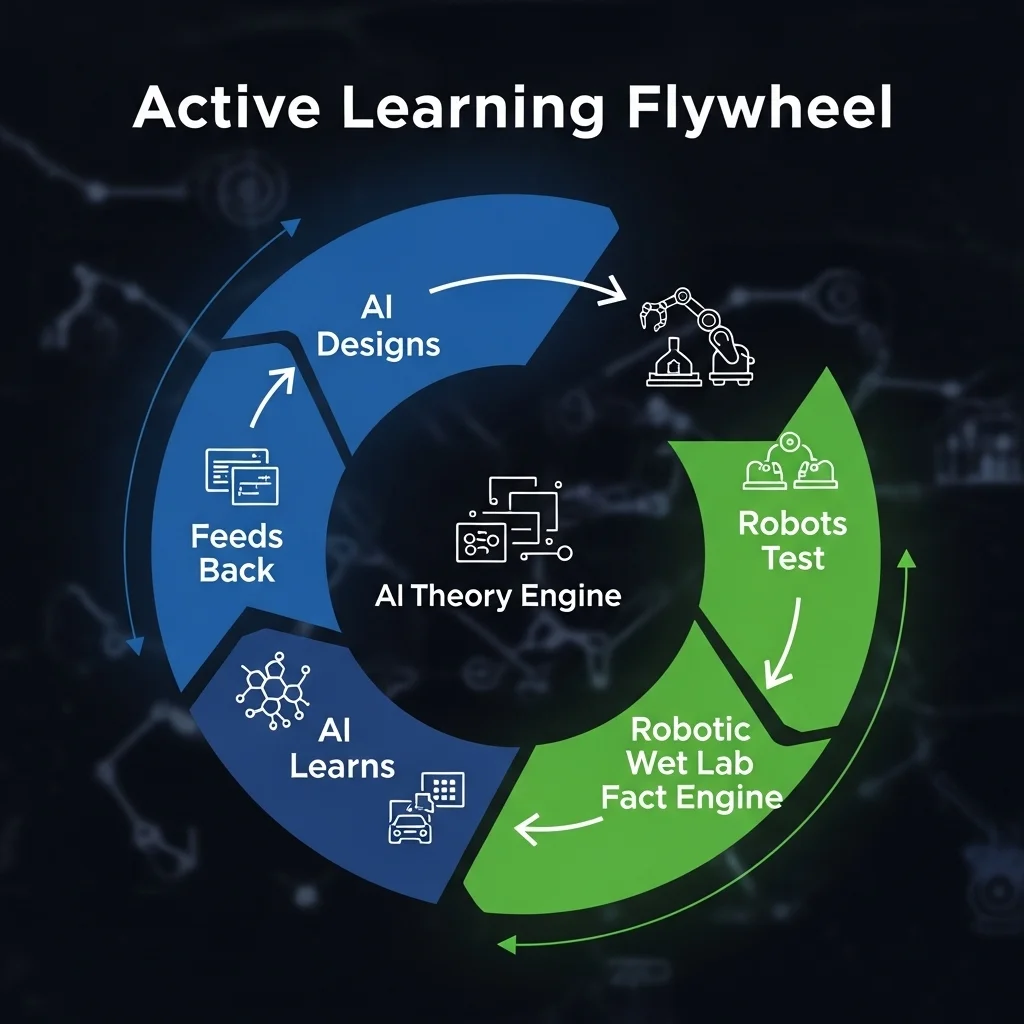
Table of Contents
- From Theory Engine to Fact Engine
- The Humanome.ai "Flywheel Effect"
- The Flywheel is Driven by Active Learning, Not Simple Retraining
- Conclusion
From Theory Engine to Fact Engine
In the previous five posts, we have detailed our in-silico design and validation stack. But a generative model is a "theory" engine. A wet lab is a "fact" engine. Any generative biology platform that exists only in silico will eventually become untethered from reality.
The "secret sauce" of Humanome.ai is not just the AI; it is the high-speed, automated "lab-in-the-loop" (LITL) that connects our theory engine to our fact engine. This is our most significant competitive advantage.
The Humanome.ai "Flywheel Effect"
We have built a "self-driving laboratory" where computational and experimental workflows are seamlessly integrated. This creates a virtuous cycle—a data flywheel.
Step 1 (AI - Design)
Our generative AI (Parts 2-4) and virtual lab (Part 5) design and filter 100 novel drug candidates optimized in silico for binding, stability, and low toxicity.
Step 2 (Lab - Validate)
Our automated, high-throughput wet lab physically synthesizes and tests all 100 of these candidates in parallel. This is not a manual process; it involves robotic orchestration of synthesis, purification, and high-throughput assays (e.g., binding affinity, thermostability, solubility).
Step 3 (AI - Learn)
The real-world experimental data—a high-dimensional matrix of what worked, what failed, and by how much—is fed back into the AI models for retraining. This loop "anchors" our in-silico predictions (e.g., predicted binding) to in-vitro "facts".
With each cycle, our virtual lab's predictions get more accurate. Our generative AI gets better at designing molecules that are not just "computable" but are stable, synthesizable, and functional in the real world.
The Flywheel is Driven by Active Learning, Not Simple Retraining
"Retraining" is a vast oversimplification. Simply adding more data to a model is inefficient. The true driver of our flywheel is Active Learning (AL), a strategy from machine learning that intelligently guides the data-gathering process.
This is the technical "how" behind our flywheel's acceleration.
Our "self-driving lab" does not just passively collect data. It intelligently asks questions.
Here is the AL process:
-
Analyze Results: In Step 3, after the data from the 100 experiments comes in, the AI analyzes it. It specifically looks for the "regions of uncertainty"—the areas where its in-silico predictions (from Part 5) were most wrong compared to the in-vitro "facts."
-
Formulate New Hypotheses: The AI then asks, "Why did I fail to predict the stability of that novel scaffold? Why was my toxicity prediction for that new chemotype incorrect?"
-
Intelligently Design Next Batch: The platform then uses our generative models to design the next batch of 100 candidates specifically to probe these regions of uncertainty. It actively designs experiments to fill its own knowledge gaps.
This AL/RL-driven loop is what makes the AI "exponentially smarter." It is not just a static tool; it is a dynamic learning system that gets more accurate with every single experiment. Our models are the best because they are constantly anchored to a high-speed, high-throughput flow of real-world biological data.
Conclusion
This technology—the generative AI, the digital twins, the robotic lab, and the active learning loop—is built, validated, and running.
In Part 7, we will show you exactly how to partner with us and put it to work on your R&D pipeline.
#activeLearning #selfDrivingLab #labAutomation #dataFlywheel #MLops

About Ryan Wentzel
Ryan previously served as a PCI Professional Forensic Investigator (PFI) of record for 3 of the top 10 largest data breaches in history. With over two decades of experience in cybersecurity, digital forensics, and executive leadership, he has served Fortune 500 companies and government agencies worldwide.
Related Articles

Beyond Structure: Why Boltz-2 and the 'Interaction Era' Matter for Drug Discovery
Boltz-2 signals a shift from static structure prediction to dynamic interaction modeling—bridging the 'Affinity Gap' that has plagued deep learning in drug discovery.
8 Min. ReadRead more →

The Silent Boom: Forensic Attribution in the Age of Bio-Cybersecurity
When the 'boom' is microscopic and delayed by months, how do you trace the provenance of synthesized pathogens? A technical deep-dive into codon bias analysis, assembly scars, and the forensic frameworks required for 'Right of Boom' response in the bioeconomy.
7 Min. ReadRead more →

The Synthetic Chemist: How Multi-Agent AI Architectures Are Automating the Hit-to-Lead Frontier
An exhaustive analysis of 'In Silico' screening, Self-Driving Laboratories, and the Agentic Era of Drug Discovery—where autonomous AI systems orchestrate entire scientific workflows from hypothesis to physical verification.
12 Min. ReadRead more →